爬取小程序数据的方法可以依据不同的需求和技术水平有所不同。以下是一些基本步骤:
1. 确定数据需求
- 明确需要爬取的数据类型,比如商品信息、评论、用户评价等。
2. 了解小程序的结构
- 小程序一般使用了复杂的前端框架,建议先通过分析网络请求的方式了解其数据结构。
3. 法律合规性
- 确保爬取行为符合相关法律法规以及小程序的使用条款,避免侵犯他人权益。
4. 采用合适的工具和技术
- 网络抓包工具:像 Fiddler 或 Charles,可以监视和分析网络请求,查看所需数据的API接口。
- Python 爬虫库:如requests等。
5. 编写爬虫程序
- 使用上述工具编写爬虫脚本,模拟浏览器请求,访问小程序背后的API。
6. 数据存储
- 根据需要选择数据存储方式(如CSV、数据库等)来保存爬取到的数据。
7. 遵守网站的爬虫策略
注意尊重网站的 robots.txt 文件,避免过于频繁的请求。
8. 处理数据
- 对爬取到的数据进行清洗和分析,提取有用信息。
下面我们以某生鲜小程序为例,看如何爬取:

一、我们以上图这个分类下的商品为目标,先打开小程序、抓包分析
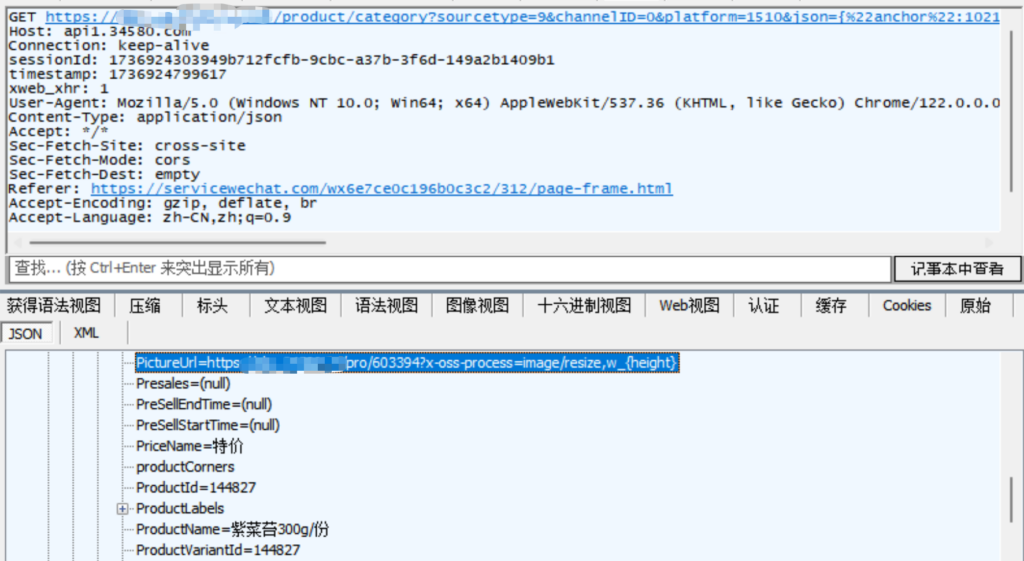
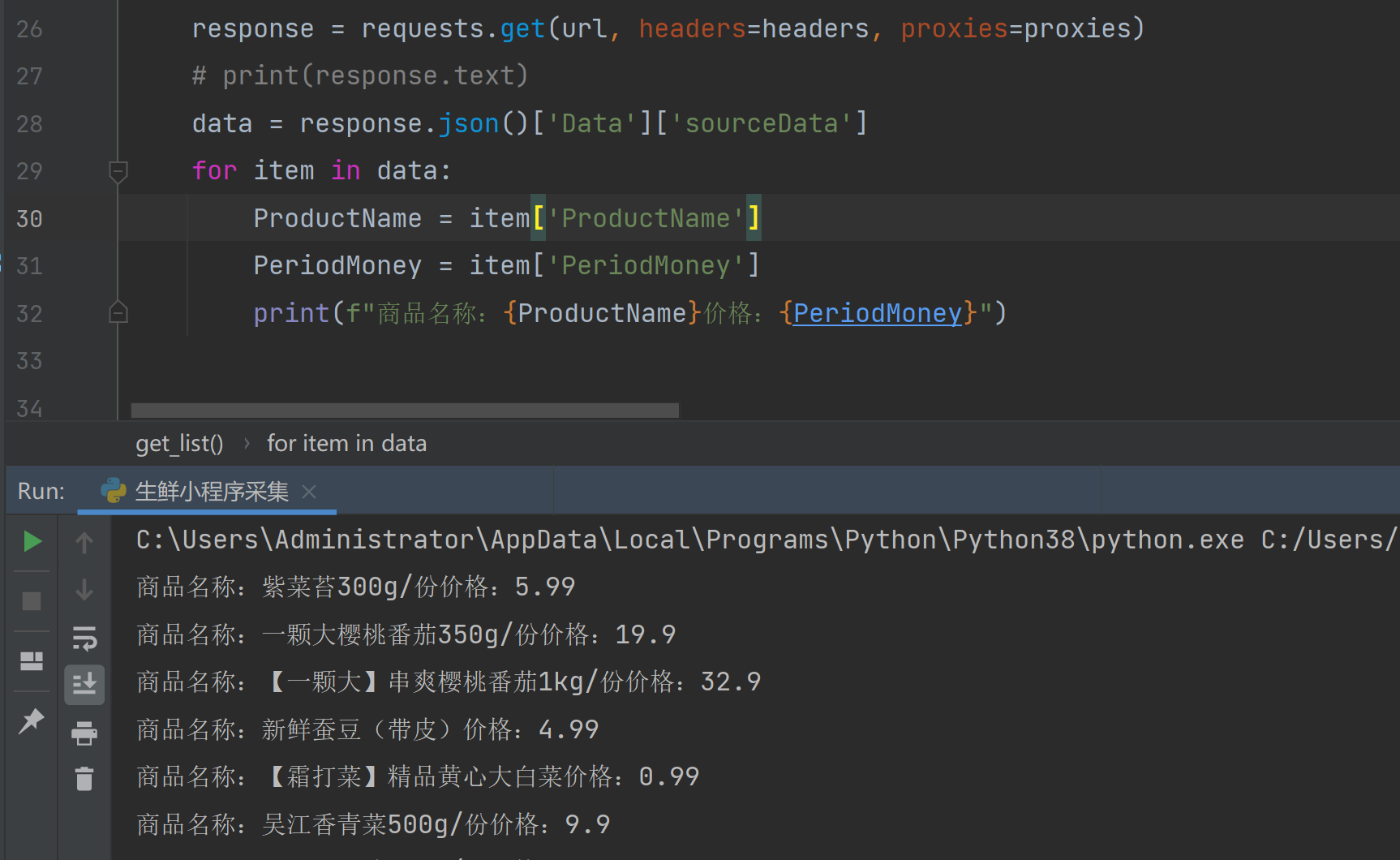
得到数据接口,然后我们分析一下该接口,先请求一下看看。
response = requests.get(url, headers=headers, proxies=proxies, params=params)
# print(response.text)
data = response.json()['Data']['sourceData']
for item in data:
ProductName = item['ProductName']
PeriodMoney = item['PeriodMoney']
print(f"商品名称:{ProductName}价格:{PeriodMoney}")

可以看到数据已经出来了。下面就是将分类id、翻页id等找到,然后构建好请求参数再一一请求即可。
json_str = "{\"anchor\":102105,\"categoryId\":102941,\"direction\":1,\"offset\":\"\",\"orderDirectionType\":0,\"orderFieldType\":0,\"pageSize\":20}"
分析一下,categoryid就是分类id,offset应该是翻页用的。下一页offset应该是19或者20
下面抓包分析一下,下一个offset是19,那就是从0开始的。
我们构建好翻页以下,再请求看看有没有地方是加密的。

很顺利,可以翻页请求到数据。那么这个分类下的数据就解决了。说明这个小程序的请求端暂时没有发现有加密的地方,数据获取就相对简单一些。
存储:
# 保存数据到csv文件
with open('生鲜小程序data.csv', 'a', encoding='utf-8') as f:
f.write(f"{ProductName},{RecommendReason}, {PeriodMoney}, {DefaultMoney}\n")
抓取到的数据可以导出:
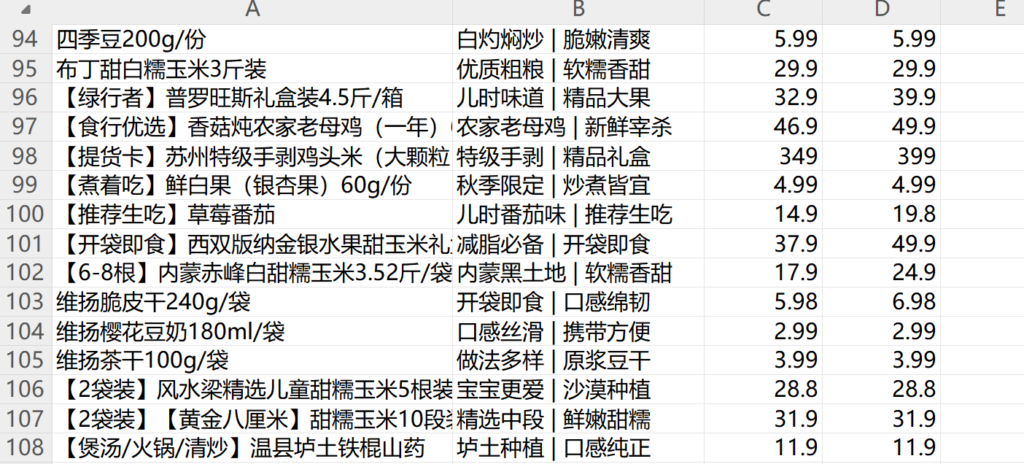
| 四季豆200g/份 | 白灼焖炒 | 脆嫩清爽 | 5.99 | 5.99 |
| 布丁甜白糯玉米3斤装 | 优质粗粮 | 软糯香甜 | 29.9 | 29.9 |
| 【绿行者】普罗旺斯礼盒装4.5斤/箱 | 儿时味道 | 精品大果 | 32.9 | 39.9 |
| 【食行优选】香菇炖农家老母鸡(一年)650g/份 | 农家老母鸡 | 新鲜宰杀 | 46.9 | 49.9 |
| 【提货卡】苏州特级手剥鸡头米(大颗粒)1.5斤礼盒装 | 特级手剥 | 精品礼盒 | 349 | 399 |
| 【煮着吃】鲜白果(银杏果)60g/份 | 秋季限定 | 炒煮皆宜 | 4.99 | 4.99 |
| 【推荐生吃】草莓番茄 | 儿时番茄味 | 推荐生吃 | 14.9 | 19.8 |
| 【开袋即食】西双版纳金银水果甜玉米礼盒4斤装 | 减脂必备 | 开袋即食 | 37.9 | 49.9 |
| 【6-8根】内蒙赤峰白甜糯玉米3.52斤/袋 | 内蒙黑土地 | 软糯香甜 | 17.9 | 24.9 |
| 维扬脆皮干240g/袋 | 开袋即食 | 口感绵韧 | 5.98 | 6.98 |
| 维扬樱花豆奶180ml/袋 | 口感丝滑 | 携带方便 | 2.99 | 2.99 |
其他分类只要更换一下分类id即可采集。
以上就是某生鲜小程序的爬取过程。其他类似的生鲜小程序也可以按上述步骤执行即可。
本文作者:微信futaike_corp,转载请保留版权声明。
来源url:https://www.futaike.net/lesson/9578.html