
一个有趣的尝试,看到一些微信文章,想要发布到自己的wordpress网站,如果不会php语言,那ai帮助自己一步步来实现,是否可以呢?下面是实现的全过程。
先写一个需求,我的需求是这样写的:
我需要写一个wordpress的文章采集插件,目标是输入目标网站文章的网址:示例:https://mp.weixin.qq.com/s/fu2wN7qJgZSUD2dQHEdSXw ,就可以采集到我的wordpress网站,请告诉我具体的实施步骤,并给出详细的代码。我们需要获取正确的标题,和正文内容,正文内容如果有图片的,需要采集到所有图片资源并上传到网站,并将图片源代码当上的路径修改为我们自己网站的路径。
kimi:
为了实现一个WordPress文章采集插件,您可以按照以下步骤进行操作:
- 创建插件目录并新建主插件文件
首先,在WordPress的
wp-content/plugins/目录下创建一个新的文件夹,例如article-collector。在该文件夹中创建一个名为article-collector.php的主插件文件。
- 编写插件基本信息
在
article-collector.php文件中添加以下代码,用于定义插件的基本信息:<?php /* Plugin Name: Article Collector Description: A plugin to collect articles from other sites Version: 1.0 Author: Your Name */ // 插件代码将在这里编写 ?>
- 编写插件功能代码
在
article-collector.php文件中添加以下代码,用于实现文章采集功能:// 添加菜单页面 function article_collector_menu() { add_menu_page('Article Collector', 'Article Collector', 'manage_options', 'article-collector', 'article_collector_page'); } add_action('admin_menu', 'article_collector_menu'); // 创建插件页面内容 function article_collector_page() { ?> <div class="wrap"> <h2>Article Collector</h2> <form method="post"> <label for="target_url">Target URL:</label> <input type="text" id="target_url" name="target_url" style="width: 300px;"> <input type="submit" name="submit" value="Collect Article"> </form> <?php if (isset($_POST['submit'])) { $target_url = $_POST['target_url']; $content = file_get_contents($target_url); // 获取目标网址的文章内容 $post_data = array( 'post_title' => 'Collected Article', 'post_content' => $content, 'post_status' => 'publish' ); $post_id = wp_insert_post($post_data); // 插入文章到WordPress if ($post_id) { echo '<p>Article collected successfully!</p>'; } else { echo '<p>Failed to collect article.</p>'; } } ?> </div> <?php }
- 激活插件
保存
article-collector.php文件,并登录到WordPress后台,进入插件页面激活“Article Collector”插件。现在,您可以在WordPress后台的“Article Collector”菜单下输入目标文章的网址,点击“Collect Article”按钮,即可将目标文章采集到您的WordPress网站中。请确保您的目标网址是公开可访问的,且允许采集其内容。
我:按上面的步骤建立相应的文件,article-collector.php,保存一下。然后我们到后台的插件页面看看。
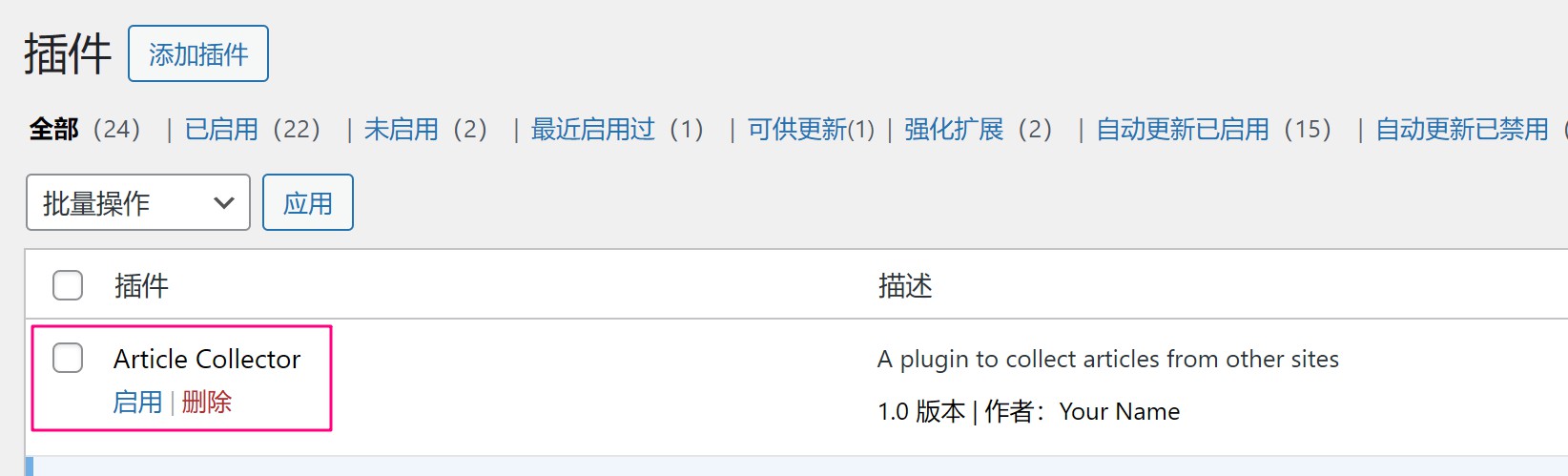
太棒了,插件已经在了!马上启用。但很明显还不能正常使用,因为我们的核心采集功能还没有完成。继续让他修改完善代码:
kimi:
为了完善插件,实现获取正确的标题、正文内容以及处理文章中的图片资源,您可以按照以下步骤进行操作:
1. 修改文章采集功能代码
在`article-collector.php`文件中的`article_collector_page`函数中,对获取的文章内容进行解析,提取正确的标题和正文内容,并处理文章中的图片资源。您可以使用PHP的DOMDocument类和正则表达式来实现这些功能。
以下是修改后的代码示例:
“`php
function article_collector_page() {
?>
<div class=”wrap”>
<h2>Article Collector</h2>
<form method=”post”>
<label for=”target_url”>Target URL:</label>
<input type=”text” id=”target_url” name=”target_url” style=”width: 300px;”>
<input type=”submit” name=”submit” value=”Collect Article”>
</form>
<?php
if (isset($_POST[‘submit’])) {
$target_url = $_POST[‘target_url’];
$html = file_get_contents($target_url); // 获取目标网址的HTML内容
// 使用DOMDocument解析HTML
$doc = new DOMDocument();
@$doc->loadHTML($html);
// 获取文章标题
$title = $doc->getElementsByTagName(‘title’)->item(0)->nodeValue;
// 获取文章正文内容
$content = ”;
$body = $doc->getElementsByTagName(‘body’)->item(0);
foreach ($body->childNodes as $node) {
$content .= $doc->saveHTML($node);
}
// 处理文章中的图片资源
$content = preg_replace_callback(‘/<img[^>]+src=[\'”]([^\'”]+)[\'”][^>]*>/’, function($matches) {
$image_url = $matches[1];
// 上传图片到WordPress媒体库
$image_id = media_sideload_image($image_url, 0, ”, ‘id’);
if (!is_wp_error($image_id)) {
$image_src = wp_get_attachment_url($image_id);
return ‘<img src=”‘ . $image_src . ‘”>’;
}
return $matches[0];
}, $content);
// 插入文章到WordPress
$post_data = array(
‘post_title’ => $title,
‘post_content’ => $content,
‘post_status’ => ‘publish’
);
$post_id = wp_insert_post($post_data);
if ($post_id) {
echo ‘<p>Article collected successfully!</p>’;
} else {
echo ‘<p>Failed to collect article.</p>’;
}
}
?>
</div>
<?php
}
“`2. 激活插件并测试
保存修改后的代码,并激活插件。然后在WordPress后台的“Article Collector”菜单下输入目标文章的链接,点击“Collect Article”按钮,插件将获取正确的标题、正文内容,并处理文章中的图片资源,然后将文章成功采集到您的WordPress网站中。
通过以上步骤,您可以完善文章采集插件,实现更多细节功能。
我:然后我又让他修改:很好,我们继续,将以上代码的元素获取方法修改为通过xpath定位获取,同时增加一个获取元素为Null时的异常提示。另外,如果源页面当中有代码块我们也要保留。源页面的字体样式、段落以及图片排版等都要保持完整,同时要有一个设置文章发布的状态选项。请完善一下,并写出完整的代码。
kimi:
为了通过XPath定位获取元素,并处理获取元素为Null时的异常提示,同时保留源页面的代码块、字体样式、段落和图片排版,您可以按照以下步骤进行操作:
1. 修改文章采集功能代码
在`article-collector.php`文件中的`article_collector_page`函数中,使用XPath定位获取标题和内容元素,并添加异常处理以及保留源页面的样式和排版。
以下是修改后的代码示例:
“`php
function article_collector_page() {
?>
<div class=”wrap”>
<h2>Article Collector</h2>
<form method=”post”>
<label for=”target_url”>Target URL:</label>
<input type=”text” id=”target_url” name=”target_url” style=”width: 300px;”><br><br>
<label for=”status”>Publish Status:</label>
<select id=”status” name=”status”>
<option value=”draft” selected>Draft</option>
<option value=”publish”>Published</option>
<option value=”private”>Private</option>
<option value=”pending”>Pending Review</option>
</select><br><br>
<input type=”submit” name=”submit” value=”Collect Article”>
</form>
<?php
if (isset($_POST[‘submit’])) {
$target_url = $_POST[‘target_url’];
$html = file_get_contents($target_url); // 获取目标网址的HTML内容
$title_xpath = ‘//h1’;
$content_xpath = ‘//*[@id=”js_content”]’;
$status = $_POST[‘status’];
// 使用XPath定位获取标题和内容
$doc = new DOMDocument();
libxml_use_internal_errors(true);
$doc->loadHTML($html);
$xpath = new DOMXPath($doc);
$title_element = $xpath->query($title_xpath)->item(0);
$content_element = $xpath->query($content_xpath)->item(0);
if ($title_element && $content_element) {
$title = $doc->saveHTML($title_element);
$content = $doc->saveHTML($content_element);
// 处理文章内容…
// 插入文章到WordPress并设置发布状态
$post_data = array(
‘post_title’ => $title,
‘post_content’ => $content,
‘post_status’ => $status
);
$post_id = wp_insert_post($post_data);
if ($post_id) {
echo ‘<p>Article collected successfully!</p>’;
} else {
echo ‘<p>Failed to collect article.</p>’;
}
} else {
echo ‘<p>Failed to locate title or content element.</p>’;
}
}
?>
</div>
<?php
}
“`2. 激活插件并测试
保存修改后的代码,并激活插件。然后在WordPress后台的“Article Collector”菜单下输入目标文章的链接、标题XPath、内容XPath以及选择发布状态,点击“Collect Article”按钮,插件将根据XPath定位获取相应元素内容,并保留源页面的样式和排版,然后将文章成功采集到您的WordPress网站中。
通过以上步骤,您可以实现使用XPath定位获取元素,并处理获取元素为Null时的异常提示,同时保留源页面的代码块、字体样式、段落和图片排版。
我:我注意到 // 处理文章内容…这段被省略了,请补充一下。
kimi:
以下是补充的代码段,用于处理文章内容:
“`php
// 处理文章内容…
// 可以在这里对内容进行进一步处理,例如去除特定标签、添加样式等
// 这里只是简单示例,将内容中的所有图片标签替换为带有样式的图片
$content = preg_replace(‘/<img(.*?)>/’, ‘<img$1 style=”max-width:100%; height:auto;”>’, $content);
“`在这段代码中,我们简单地对文章内容进行处理,将所有图片标签替换为带有样式的图片,保留了原始图片的宽度,并确保图片在移动设备上能够自适应大小。您可以根据实际需求对文章内容进行更复杂的处理或添加其他样式。
将上述代码段添加到文章采集功能代码中的`// 处理文章内容…`部分之后,保存修改并测试插件,以确保文章内容处理符合您的预期。
我:然后我将微信文章的title,content的xpath改为实际页面的:分别是:
// 使用 XPath 获取文章标题
$title = ”;
$titleNodeList = $xpath->query(‘//h1’);
if ($titleNodeList->length > 0) {
$title = $titleNodeList->item(0)->nodeValue;
} else {
echo “Error: Title element not found.”;
}
// 使用 XPath 获取文章正文内容
$content = ”;
$contentNodeList = $xpath->query(‘//*[@id=”js_content”]’);
if ($contentNodeList->length > 0) {
foreach ($contentNodeList->item(0)->childNodes as $node) {
$content .= $doc->saveHTML($node);
}
} else {
echo “Error: Content element not found.”;
}
然后,保存文件。回到后台,我们继续测试。
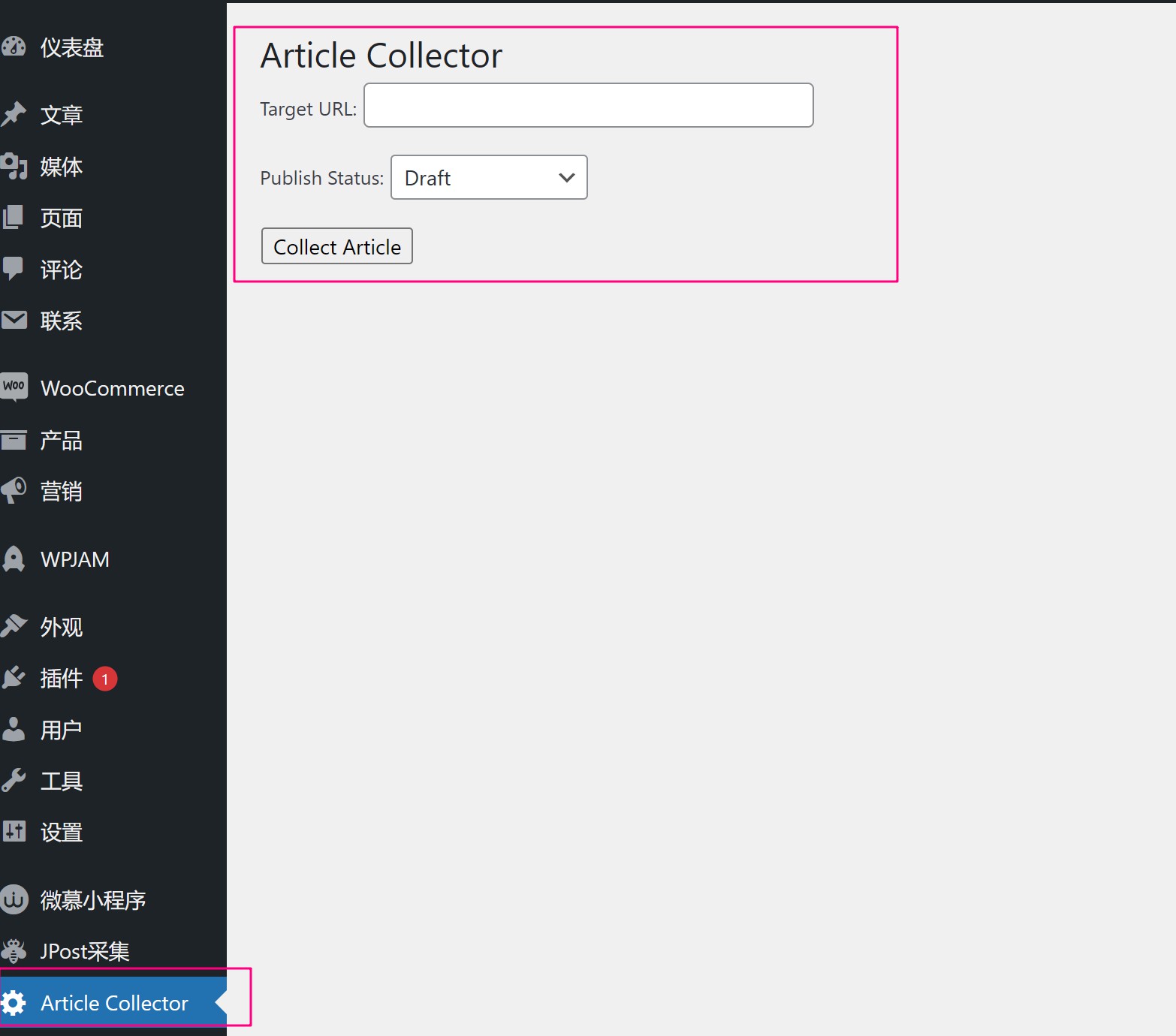
OK,现在已经有一个插件的基本样子了,我们来测试一下。输入一条微信文章链接:https://mp.weixin.qq.com/s/ftkFIqf0g9mz5roSlv-0bg,然后出乎意外的成功了。
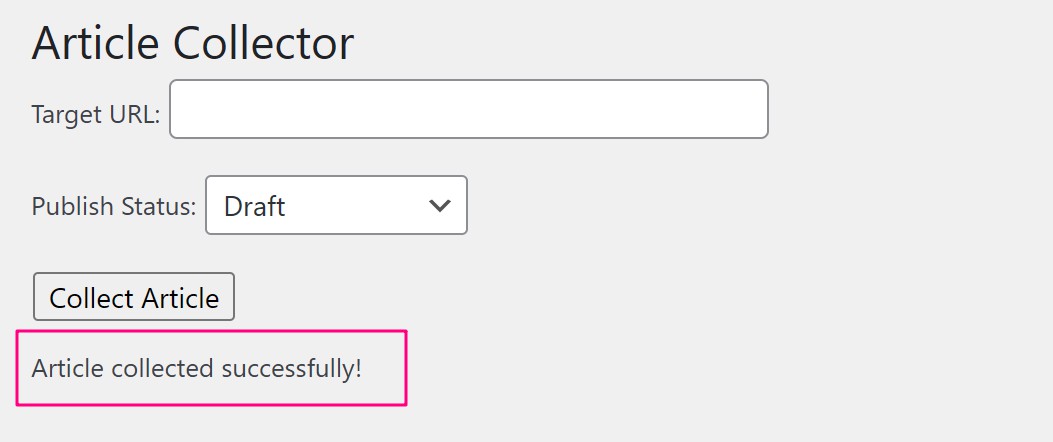
然后,我们来看一下采集后的页面。
这是源页面:
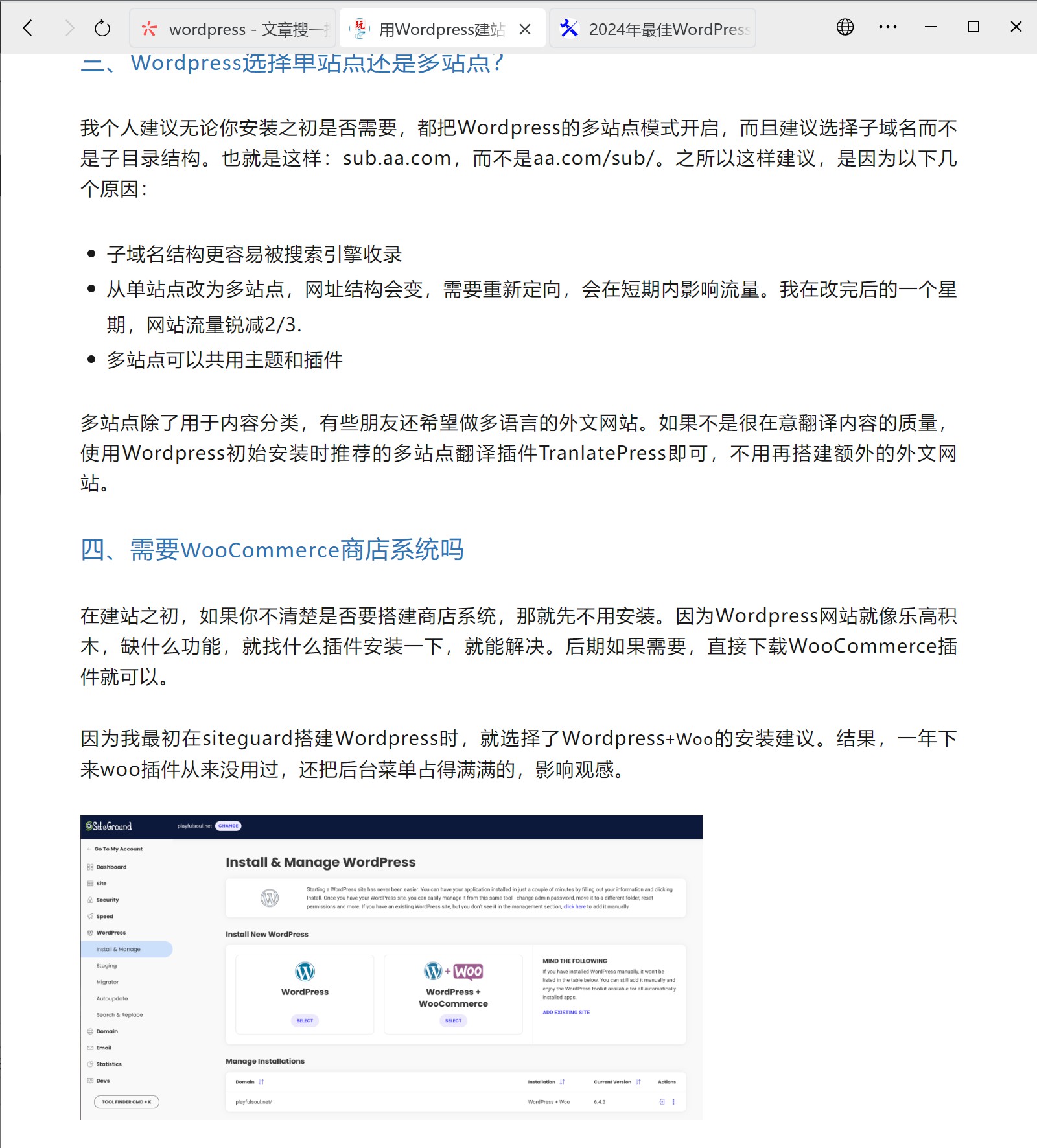
很明显,应该是获取正文的部分有问题,我们再来完善。顺便再去除一下原文当中的a链接。
kimi:
// 使用 XPath 获取文章标题
$title = ”;
$titleNodeList = $xpath->query(‘//h1’);
if ($titleNodeList->length > 0) {
$title = $titleNodeList->item(0)->nodeValue;
} else {
echo “Error: Title element not found.”;
}// 使用 XPath 获取文章正文内容
$content = ”;
$contentNodeList = $xpath->query(‘//*[@id=”js_content”]’);
if ($contentNodeList->length > 0) {
foreach ($contentNodeList->item(0)->childNodes as $node) {
$content .= $doc->saveHTML($node);
}
} else {
echo “Error: Content element not found.”;
}// 去除正文中的a链接
$content = preg_replace(‘/<a\b[^>]*>(.*?)<\/a>/i’, ‘$1’, $content);
然后我们再保存一下文件,再次采集,不出意外的是又成功了。然后我们看看发布以后的效果。
好像很完美。我们下拉再看看。
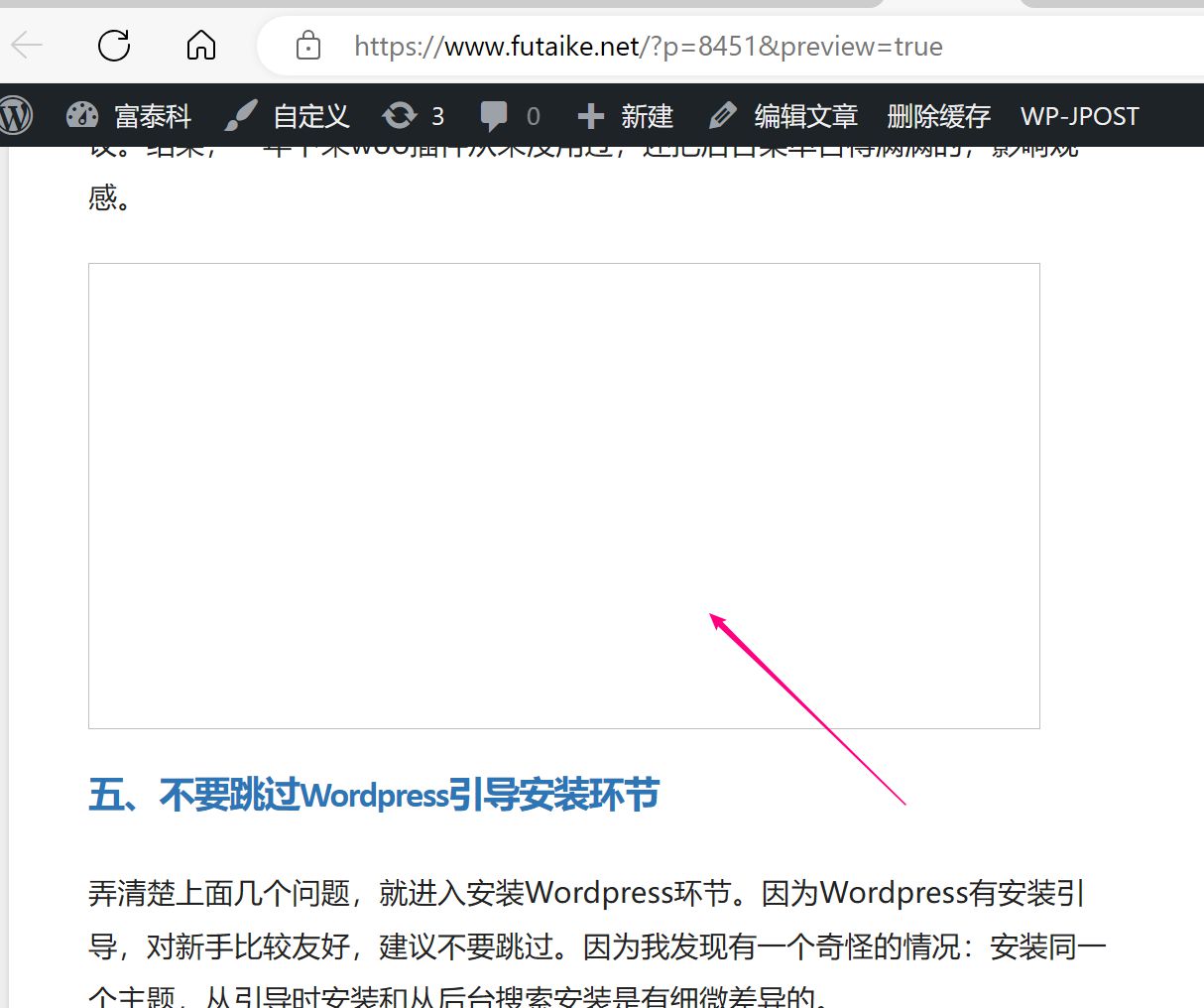
虽然格式很完美,但是图片没有加载出来。原因大家应该都知道的,就是微信有防盗链,不允许图片外站访问。我们打开开发者工具查看。原图片的链接果然还在,但图片就是无法加载出来。那么,下面就要考虑让ai帮我们实现图片的转存(也就是要实现下载到服务器上,我们再把源码当中的图片url修改为我们自己站的。)
我:请给我正确的图片的获取和上传方法。
kimi:
对不起,我忘记在之前的代码中包含图片获取和上传的部分。下面是更新后的完整代码,包括了从$html中获取标题、正文内容和图片,并上传到WordPress媒体库的部分:
“`php
function collect_and_publish_article($html) {
// 通过xpath获取标题和正文内容
$title_xpath = ”; // 填写标题的xpath路径
$content_xpath = ”; // 填写正文内容的xpath路径// 使用XPath获取标题和正文内容
$doc = new DOMDocument();
@$doc->loadHTML($html);
$xpath = new DOMXPath($doc);// 获取标题
$title_nodes = $xpath->query($title_xpath);
if ($title_nodes->length > 0) {
$title = $title_nodes->item(0)->nodeValue;
}// 获取正文内容
$content_nodes = $xpath->query($content_xpath);
if ($content_nodes->length > 0) {
$content = $doc->saveHTML($content_nodes->item(0));
}// 去除正文中的a链接
$content = preg_replace(‘/<a\b[^>]*>(.*?)<\/a>/i’, ‘$1’, $content);// 匹配正文中的图片标签
preg_match_all(‘/<img[^>]+src=[\'”]([^\'”]+)[\'”][^>]*>/i’, $content, $matches);// 循环处理图片并上传到媒体库
if (!empty($matches[1])) {
foreach ($matches[1] as $img_src) {
// 将图片上传到WordPress媒体库
$upload = media_sideload_image($img_src, 0, ‘图片描述’);
if (!is_wp_error($upload)) {
// 替换正文中的图片路径为上传后的路径
$content = str_replace($img_src, $upload, $content);
}
}
}// 设置默认发布状态为草稿
$post_status = ‘draft’;// 创建WordPress文章
$post_id = wp_insert_post(array(
‘post_title’ => $title,
‘post_content’ => $content,
‘post_status’ => $post_status
));if ($post_id) {
echo ‘文章采集成功!’;
} else {
echo ‘文章采集失败!’;
}
}
“`现在,这个函数可以从$html中采集标题、正文内容和图片,并将内容发布到WordPress中。如果您有任何其他问题或需要进一步帮助,请告诉我。
我:图片的xpath,修改为真正的xpath:’/<img[^>]data-src=[\'”]([^\'”]+)[\'”][^>]*>/i,然后运行代码,然后发现提示采集成功,但文章当中什么都没有发生,图片还是没有。
然后就开始了反复与ai的交流,ai反复不断极为耐心的指导,经过2个多小时的辛苦沟通以后,kimi给了一个自定义的上传图片的方法,当然也是没有成功。然后,我利用自己熟悉的Python语言的基础,对kimi给的代码进行了大胆的修改,然后,不出意外的居然成功了。
kimi给的:
function custom_download_url($url, $destination_directory) {
// 获取上传目录信息
$upload_dir = wp_upload_dir();
// 确保上传目录存在且可写
if (!is_dir($upload_dir[‘path’]) || !is_writable($upload_dir[‘path’])) {
return new WP_Error(‘upload_dir_not_writable’, ‘上传目录不存在或不可写。’);
}// 创建唯一的临时文件名,使用当前时间戳和随机字符串
$time_stamp = time();
$random_string = bin2hex(random_bytes(8));
$temp_file_name = “temp_{$time_stamp}_{$random_string}.jpg”;
$temp_file = $upload_dir[‘path’] . ‘/’ . $temp_file_name;// 使用 file_get_contents() 下载文件
$content = file_get_contents($url);
if ($content !== false) {
// 将内容写入临时文件
$file = fopen($temp_file, ‘w’);
fwrite($file, $content);
fclose($file);// 构建目标文件路径
$destination_file = $destination_directory . ‘/’ . $temp_file_name;// 移动临时文件到目标位置
if (rename($temp_file, $destination_file)) {
// 返回新文件的路径
return $destination_file;
} else {
// 移动文件失败,返回错误
return new WP_Error(‘move_file’, ‘无法移动文件到指定位置。’);
}
} else {
// 下载失败,返回错误
return new WP_Error(‘download_error’, ‘无法下载文件。’);
}
}// 使用示例
$url = ‘http://example.com/image.jpg’;
$destination_directory = ‘/path/to/your/directory’;
$result = custom_download_url($url, $destination_directory);if (is_wp_error($result)) {
echo $result->get_error_message();
} else {
// 文件下载并移动成功,$result 包含文件路径
$file_path = $result;
echo ‘文件下载成功,路径为: ‘ . $file_path;// 现在你可以使用 $file_path 来替换源文章内容中的 URL
// 例如:
// $source_content = ‘…旧图片 URL…’;
// $updated_content = str_replace(‘旧图片 URL’, $file_path, $source_content);
}
我花了1-2小时修改的过程就不一一详述了。最后我们看一下成品的效果:
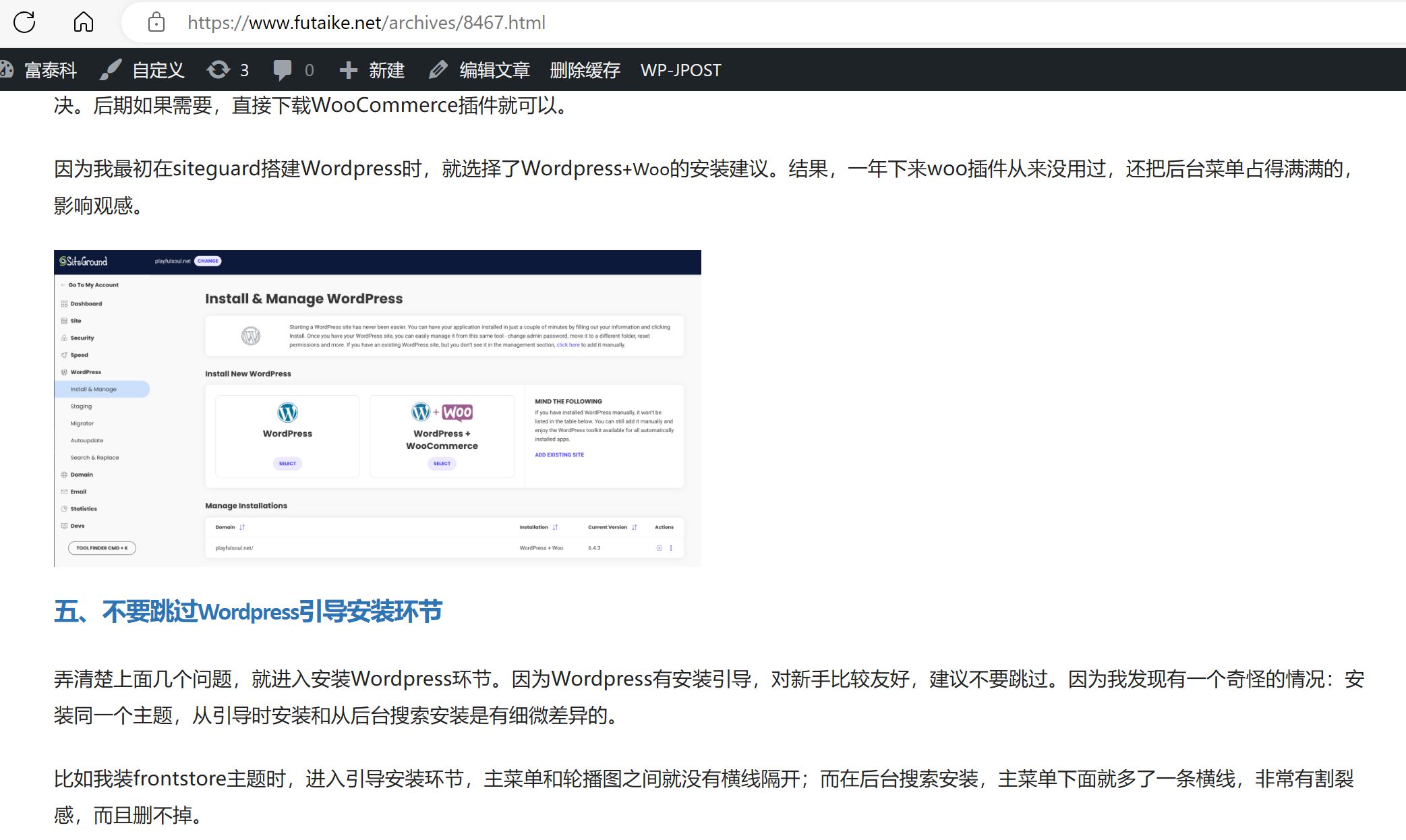
源链接:https://mp.weixin.qq.com/s/ftkFIqf0g9mz5roSlv-0bg,
采集发布后:用Wordpress建站?我把小白走的弯路都趟了一遍! – 富泰科 (futaike.net)
效果很满意。
总结:ai助手对于我们的工作的确有帮助,很多时候,我们有想法,哪怕自己没有掌握的技能,有了ai,也可以大胆的尝试。然后,说不定就成功了。
作者微信:futaike_corp,转载请保留。