项目一:awesome-python-login-model
该开源项目主要用于模拟登录,主要技术为 selenium,处理了很多网站的 JS 逆向问题。
整体策略围绕登录,保存 cookie,维护 cookie 进行采集实施。作者在项目描述页为大家分享了已经实现的网站,例如猎聘,CSDN,京东,拉钩,微博等爬虫经常光顾的网站。
项目开源协议为 GNU,最近一次更新时间为 11 天前(文章写作时间为 2021 年 7 月 9 日,下同)
项目地址:https://github.com/Kr1s77/awesome-python-login-model。
项目 Star:13.5K,Fork 3K。
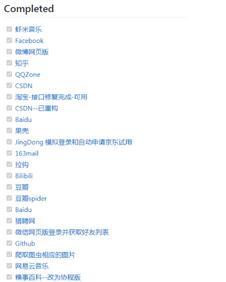
已解决登录网站列表:
项目二:proxy_pool
Python 爬虫代理池,核心功能定时采集网上发布的免费代理,验证是否可用,然后自建代理池,提供了 API 和 CLI 两种方式。
作者非常友好的提供了 Python2.x 和 Python3.x 版本,以及项目文档 https://proxy-pool.readthedocs.io/zh/latest/。
为了便于测试效果,同步开放了一个测试地址 http://demo.spiderpy.cn。
项目开源协议为 MIT,最近一次更新时间为 16 小时前。
项目地址:https://github.com/jhao104/proxy_pool。
项目 Star:12.8K,Fork 3.6K。
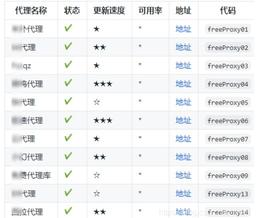
目前内置的免费代理源如下(手动打码):
项目三:weibo-crawler
新浪微博爬虫,它可以连续爬取一个或者多个新浪微博用户数据,该项目优秀在持续更新,对于爬取内容可以自行定制,并且可扩展为增量数据爬虫。
爬虫兼容了微博图片下载与视频下载,可学习的点非常多。
项目开源协议为 未设置,最近一次更新时间为 10 小时前。
项目地址:https://github.com/dataabc/weibo-crawler。
项目 Star:1.2K,Fork 390。
该作者贡献了很多面向微博的爬虫,可以多翻翻,非常好的学习对象,例如:https://github.com/dataabc/weiboSpider 。
作者对于功能的描述:

项目四:WechatSogou
基于搜索微信搜索的微信公众号爬虫接口,该开源项目主要用于采集微信公众号文章。
项目最近更新不频繁,是否可用有待测试,但是开源代码是非常值得学习的,由于该项目的协议不是无限制协议,所以大家以学习编码的目的看待该项目即可。
项目开源协议为 Apache-2.0 License。
项目地址:https://github.com/chyroc/WechatSogou。
项目 Star:5.1K,Fork 1.6K。
基于微信公众号文章的爬虫项目,还可以参考 https://github.com/wnma3mz/wechat_articles_spider ,该项目也是基于 Apache-2.0 License,该项目作者标记更新于 2021年3月,参考学习还是非常有价值的。
项目 Star:1.2K,Fork 395。
项目五:Image-Downloader
该项目用于从百度,谷歌,必应下载图片,核心使用到的库是 Requests、Selenium,学习该项目的原因是它提供了 GUI 和 CMD 两个版本,即你可以通过 GUI 界面操作爬虫,非常好的学习资源。
项目开源协议为 MIT License + 996ICU License,即 996 公司不可使用。
项目地址:https://github.com/sczhengyabin/Image-Downloader。
项目 Star:1.3K,Fork 374。
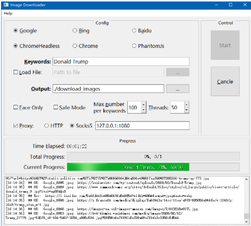
项目运行截图
项目六:dianping_spider
大众点评爬虫(全站可爬,解决动态字体加密,非 OCR)。作者正在更新中,可以通过开源项目学习字体反爬。因为大众点评反爬相当严格,所以作者也加上了 cookie 池,ip 代理,这都是非常好的学习素材。
项目开源协议为 GPL-3.0 License。
项目地址:https://github.com/Sniper970119/dianping_spider。
项目 Star:184,Fork 34。
作者公布的已完成功能清单:

文章来源:https://blog.csdn.net/hihell/article/details/118595568