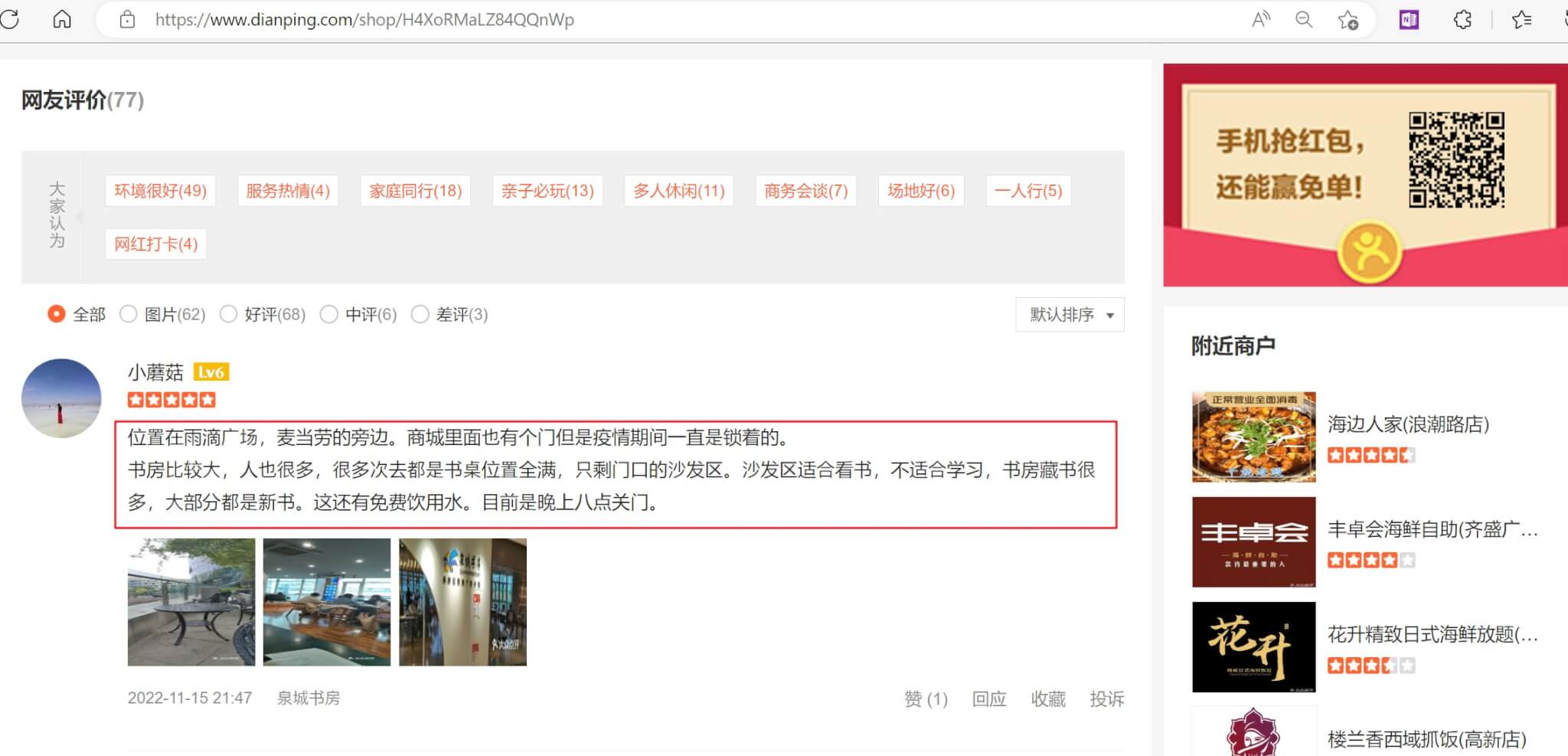
如今大众点评的评论信息做了前端字体加密,爬取大众点评用户评论有几个难点:
- 查看完整评论和更多评论需要登陆后才可以
- 评论数据不完整,部分文字被替换
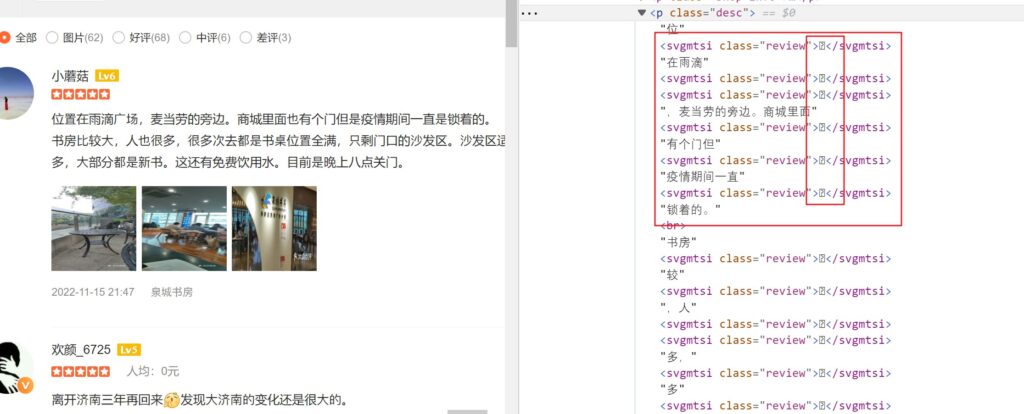
如下图:部分字体被<span>标签包含,实际它是一张svg背景图,用css样式控制雪花图显示加载,并且可以看到他的css的background属性,可自行更改看看效果,注意字体width:14px。
思路:
- 获取评论部分的完整HTML样式,把整个内容用list存起来;
-
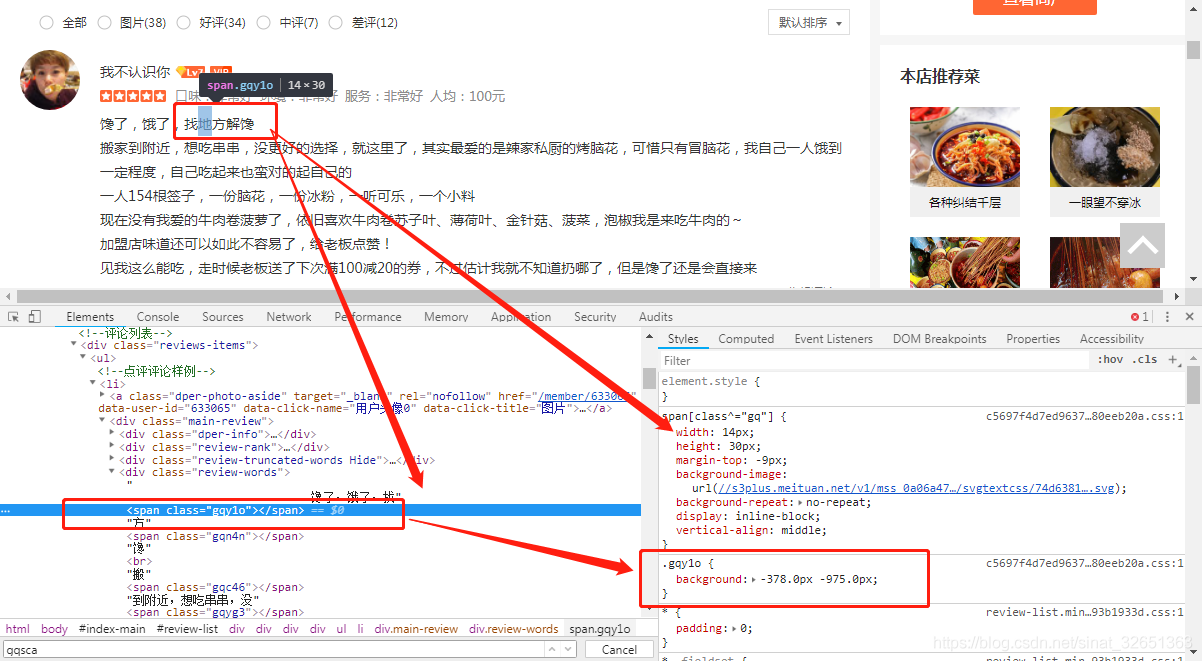
获取css样式,样式在源码的位置,如下图,我们需要的是每个span标签里的class属性值,因为它对应background坐标信息。
-
从css样式中动态取svg图片链接,生成字典库,然后用第二步的css坐标经过处理,查找真实字所对应的值,并返回最终真实评论。
步骤:
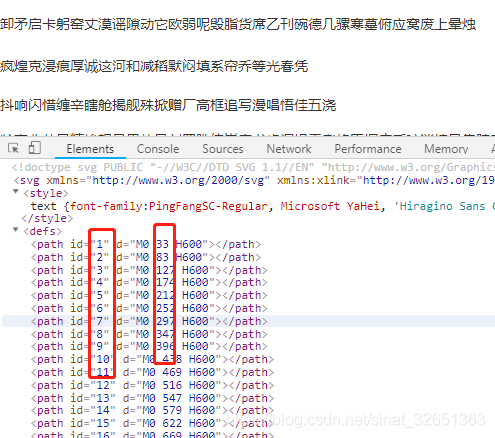
图一各标签位置还是需要了解一下的。
一、查看源码,知道css样式链接在哪里,保存该链接。

二、第一步获取的css链接样式里会有一个background-image标签,里面包含加密字体的svg路径,保存该路径,同时将该css文件的.*****{background:-,-}做成字典保存起来。
敲黑板了:图片一中提到过字体样式宽度为14px,因此我们把获取的background的x坐标/14,就是最终加密字体svg中的位置,svg每一行的字符串可转为数组存储,这样就能建立对应关系。background的y坐标要和svg中的<path>中的值比较,后续说。
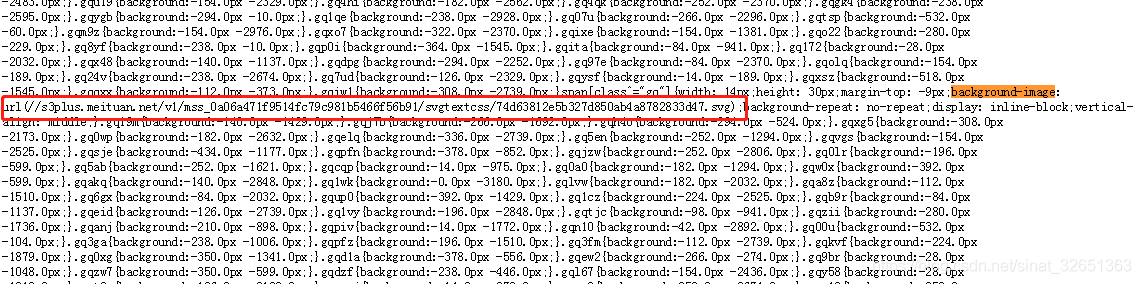
三、这是加密字体的svg文件,注意看<path> 标签,它的id对应后面<textPath>标签的href值,它的d值就很有意思,也是解密的关键。
敲黑板了:步骤二中提到过background的y值,再和d列的M0后面值做比较就有意思了,比如
.gqi4j {background: -98.0px -130.0px;} 中的y:-130,取正数130,小于<path>标签中的d属性第二列的174这个值,则对应加密字库实际y轴为174,对应的id=4,就是<textPath>中的href标签,也就是加密字体的y轴坐标,而它的x就是98/14,对应的id=4,href=”#4″行里的低98/14个的值,至此一个加密的字就取出来了。

最终效果:
如下图,完整评论内容,右侧部分没显示完部分,需要点开更多评论,原网页中有两个标签,一个完整的,一个局部的。
#!/usr/bin/env python
# encoding: utf-8
"""
@version: v1.0
@author: W_H_J
@license: Apache Licence
@contact: 415900617@qq.com
@software: PyCharm
@file: dazhongdianping.py
@describe: 大众点评评论抓取-解析
"""
import sys
import os
import re
import requests
from pyquery import PyQuery as pq
sys.path.append(os.path.abspath(os.path.dirname(__file__) + '/' + '..'))
sys.path.append("..")
header_pinlun = {
'Host': 'www.dianping.com',
'Accept-Encoding': 'gzip',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36'
}
header_css = {
'Host': 's3plus.meituan.net',
'Accept-Encoding': 'gzip',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36'
}
# 0-详情页
def get_msg():
"""
url: http://www.dianping.com/shop/+ 商铺ID +/review_all
:return:
"""
# url = "http://www.dianping.com/shop/110620927/review_all"
url = "http://www.dianping.com/shop/96658933/review_all"
# url = "https://www.dianping.com/shop/77307732/review_all"
html = requests.get(url, headers=header_pinlun)
print("1 ===> STATUS", html.status_code)
doc = pq(html.text)
# 解析每条评论
pinglunLi = doc("div.reviews-items > ul > li").items()
"""
调用评论里的css样式处理和加密字体svg处理
:return:
dict_svg_text: svg整个加密字库,以字典形式返回
list_svg_y:svg背景中的<path>标签里的[x,y]坐标轴,以[x,y]形式返回
dict_css_x_y:css样式中,每个加密字体的<span> 标签内容,用于匹配dict_svg_text 中的key,以字典形式返回
"""
dict_svg_text, list_svg_y, dict_css_x_y = css_get(doc)
for data in pinglunLi:
# 用户名
userName = data("div.main-review > div.dper-info > a").text()
# 用户ID链接
userID = "http://www.dianping.com" + data("div.main-review > div.dper-info > a").attr("href")
# 用户评分星级[10-50]
startShop = str(data("div.review-rank > span").attr("class")).split(" ")[1].replace("sml-str", "")
# 用户描述:机器:非常好 环境:非常好 服务:非常好 人均:0元
describeShop = data("div.review-rank > span.score").text()
# 关键部分,评论HTML,待处理,评论包含隐藏部分和直接展示部分,默认从隐藏部分获取数据,没有则取默认部分。(查看更多)
pinglun = data("div.review-words.Hide").html()
try:
len(pinglun)
except:
pinglun = data("div.review-words").html()
# 该用户喜欢的美食
loveFood = data("div.main-review > div.review-recommend").text()
# 发表评论的时间
pinglunTime = data("div.main-review > div.misc-info.clearfix > span.time").text()
print("userName:", userName)
print("userID:", userID)
print("startShop:", startShop)
print("describeShop:", describeShop)
print("loveFood:", loveFood)
print("pinglunTime:", pinglunTime)
print("pinglun:", css_decode(dict_css_x_y, dict_svg_text, list_svg_y, pinglun))
print("*"*100)
# 1-评论隐含部分字体css样式, 获取svg链接,获取加密汉字background
def css_get(doc):
css_link = "http:"+doc("head > link:nth-child(11)").attr("href")
background_link = requests.get(css_link, headers=header_css)
r = r'background-image: url(.*?);'
matchObj = re.compile(r, re.I)
svg_link = matchObj.findall(background_link.text)[0].replace(")", "").replace("(", "http:")
"""
svg_text() 方法:请求svg字库,并抓取加密字
dict_svg_text: svg整个加密字库,以字典形式返回
list_svg_y:svg背景中的<path>标签里的[x,y]坐标轴,以[x,y]形式返回
"""
dict_avg_text, list_svg_y = svg_text(svg_link)
"""
css_dict() 方法:生成css样式中background的样式库
dict_css: 返回css字典样式
"""
dict_css = css_dict(background_link.text)
return dict_avg_text, list_svg_y, dict_css
# 2-字体库链接
def svg_text(url):
html = requests.get(url)
dict_svg, list_y = svg_dict(html.text)
return dict_svg, list_y
# 3-生成svg字库字典
def svg_dict(csv_html):
svg_text_r = r'<textPath xlink:href="(.*?)" textLength="(.*?)">(.*?)</textPath>'
svg_text_re = re.findall(svg_text_r, csv_html)
dict_avg = {}
# 生成svg加密字体库字典
for data in svg_text_re:
dict_avg[data[0].replace("#", "")] = list(data[2])
"""
重点:http://s3plus.meituan.net/v1/mss_0a06a471f9514fc79c981b5466f56b91/svgtextcss/74d63812e5b327d850ab4a8782833d47.svg
svg <path> 标签里内容对应css样式中background的y轴参数,小于关系,
如果css样式中的background的y参数小于 svg_y_re 集合中最小的数,则向上取y轴,('18', 'M0', '748', 'H600'),
如.gqi4j {background: -98.0px -745.0px;} 中的y-745,取正数745,小于748,则对应加密字库实际y轴为748,对应的18就是<textPath>中的x轴
"""
svg_y_r = r'<path id="(.*?)" d="(.*?) (.*?) (.*?)"/>'
svg_y_re = re.findall(svg_y_r, csv_html)
list_y = []
# 存储('18', 'M0', '748', 'H600') eg:(x坐标,未知,y坐标,未知)
for data in svg_y_re:
list_y.append([data[0], data[2]])
return dict_avg, list_y
# 4-生成css字库字典
def css_dict(html):
css_text_r = r'.(.*?){background:(.*?)px (.*?)px;}'
css_text_re = re.findall(css_text_r, html)
dict_css = {}
for data in css_text_re:
"""
加密字库.gqi4j {background: -98.0px -745.0px;}与svg文件对应关系,x/14,就是svg文件加密字体下标
y,原样返回,需要在svg函数中做处理
"""
x = int(float(data[1])/-14)
"""
字典参数:{css参数名:(background-x,background-y,background-x/14,background-y)}
"""
dict_css[data[0]] = (data[1], data[2], x, data[2])
return dict_css
# 5-最终评论汇总
def css_decode(css_html, svg_dict, svg_list, pinglun_html):
"""
:param css_html: css 的HTML源码
:param svg_dict: svg加密字库的字典
:param svg_list: svg加密字库对应的坐标数组[x, y]
:param pinglun_html: 评论的HTML源码,对应0-详情页的评论,在此处理
:return: 最终合成的评论
"""
css_dict_text = css_html
csv_dict_text, csv_dict_list = svg_dict, svg_list
# 处理评论源码中的span标签,生成字典key
pinglun_text = pinglun_html.replace('<span class="', ',').replace('"/>', ",").replace('">', ",")
pinglun_list = [x for x in pinglun_text.split(",") if x != '']
pinglun_str = []
for msg in pinglun_list:
# 如果有加密标签
if msg in css_dict_text:
# 参数说明:[x,y] css样式中background 的[x/14,y]
x = int(css_dict_text[msg][2])
y = -float(css_dict_text[msg][3])
# 寻找background的y轴比svg<path>标签里的y轴小的第一个值对应的坐标就是<textPath>的href值
for g in csv_dict_list:
if y < int(g[1]):
# print(g)
# print(csv_dict_text[g[0]][x])
pinglun_str.append(csv_dict_text[g[0]][x])
break
# 没有加密标签
else:
pinglun_str.append(msg.replace("\n", ""))
str_pinglun = ""
for x in pinglun_str:
str_pinglun += x
# 处理特殊标签
dr = re.compile(r'</?\w+[^>]*>', re.S)
dr2 = re.compile(r'<img+[^;]*', re.S)
dr3 = re.compile(r'&(.*?);', re.S)
dd = dr.sub('', str_pinglun)
dd2 = dr2.sub('', dd)
pinglun_str = dr3.sub('', dd2)
return pinglun_str
if __name__ == '__main__':
get_msg()完整项目github:https://github.com/Liangchengdeye/DaZhongdianping.git
前两篇博文:
大众点评评论抓取,这个是老版本的,但是注意点还是可以看看的,以免被反爬。
本篇博文更新于2018/12/20,针对目前加密方式可行,未来不可知。
作者:凉城的夜
微信扫描下方的二维码阅读本文
